像大多数解析相关的程序一样,Parboiled 严重依赖于图和树结构。第一个这样的结构会在解析过程中创建,即规则“树”。该规则树这时尚未与实际的输入产生依赖。解析输入会在解析执行的过程中被解析器消费并被应用到规则树上,该过程可以以可选的方式生成一个解析树。
假设以下示例语法:
1 | a ← b ‘a’ c |
如果你将该语法转换为一个图,仅将规则作为图的节点,规则引用作为有向边,这时该语法可以用以下结构来表示:
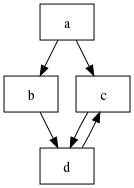
你会发现该图存在一个环,同时节点 d 拥有两个父亲,这也就是为什么该图不是一个树而仅仅是一个有向图。很多真实世界的语法的大多部分都像是一个树,带有非常清晰的规则到子规则层级引用。虽然回环(递归)并不十分罕见,但与“常规”分层引用相比,它们的数量确实很少。
因此这样的原因(以及对许多人而言,“树”是一种更常见的心理图景),你可能会选择将这样的规则图看做是带有两个特殊异常的规则树:多父亲、回环。
顺便提一下,PEG 语法的这种有向图特性几乎与方法调用在 JVM 中的工作方式一致:方法调用其他方法,可能包括调用堆栈祖先。这也是为什么 Parboiled 会或多或少的将规则声明映射到 Java/Scala 的方法调用。你的每个解析器规则方法都会构造一个规则对象,并在构造过程中潜在的调用其他规则构造方法。
然而这里还有两个问题:
- Java/Scala 方法递归到方法自身或其祖先时需要一种方式来终止递归。通常这是通过一些逻辑实现的,可以在逻辑中通过一些条件来退出递归。然而规则声明无法做到这一点,只有解析的输入文本(是有限的)将会终止任何规则递归。因此为了防止用于构造规则的 Java/Scala 方法出现无限递归,需要采取一些技巧。
- 当一个规则构造方法被调用多次时(可能被多起其他规则构造方法调用),通常会为每次调用创建结构相同的全新的规则实例。虽然这不是什么问题,但在规模较大的语法中则会比较低效,这时一个大型的规则树中会包含很多重复的规则实例。
Parboiled 在 Java 中通过重写解析类的规则方法来、并注入开发者不可见的代码来解决这两个问题。这些代码会确保每个方法仅会被调用一次,即背个规则仅被创建一次,后续的调用则会返回已创建的相同规则实例。如果规则的创建过程递归会自身,则插入代理规则以防止无限递归。所有这些事情都在幕后透明地发生,开发者无需关心。
Parboiled 在 Scala 中则不需要重写实际的字节码,而是将实际的规则创建代码封装到一个函数块,并作为主规则构建方法的参数。
最后,当你调用你的顶级规则方法并传给所选的 ParseRunner 时,则会得到一个规则树,没有重复节点,正确的链接关系,甚至还有递归。
Mathcers
你可能已经在 Javadoc API 文档中看到 Rule 接口仅仅是一个外观接口,带有很少的方法以指定特殊的规则属性。所有实现该接口的类被定义在 org.parboiled.matchers 中。有一个用于所有规则原语的 Matcher 实现,它实现了实际规则类型的逻辑。因此规则树实际上是一个 Matcher 树。然而,大多时候你不必了解这些内部细节,仅需关注于解析器规则和值栈。