CH04-分离标识与状态
在此要特别强调不纯粹的函数是语言与命令式语言的区别。在命令式语言中,变量默认都是状态易变的,代码会经常修改变量。而在不纯粹的函数式语言中,变量默认是状态不易变的,代码仅在十分必要时才修改变量。
本节将介绍如何使用可变量和持久数据结构来分离状态与标识。采用这些技术,多线程可以不使用锁来访问可变量,同时也不会出现隐藏可变状态或逃逸可变状态。
基本组件
原子变量
持久数据结构
这里所说的持久并不是指将数据持久化到磁盘或保存到数据库中,而是指数据结构在被修改时总是保留其之前的版本,从而为代码提供一致的数据视角。
持久数据结构在被修改时,看上去就像是创建了一个完整的副本。如果持久数据结构在实现时也是创建完整的副本,将会非常低效且带来很大的使用限制。幸运的是,持久数据结构选择了更精巧的方法,即“共享结构”。
比如创建一个列表:
1 | (def listv1 (list 1 2 3)) |
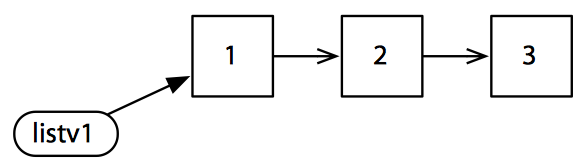
先现在使用 cons 创建一个上述列表的修改版,cons 返回列表的副本并在副本的首部添加一个元素:
1 | (def listv2 (cons 4 listv1)) |
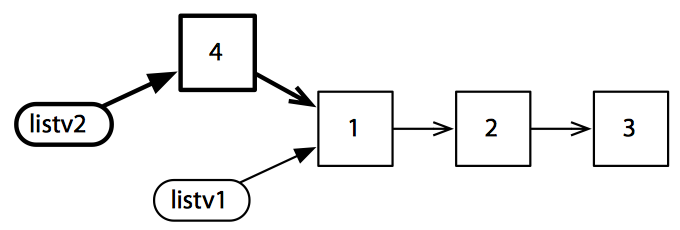
新列表可以完全共享原列表的元素——不需要进行复制,如上图所示。
下面再尝试创建一个修改版:
1 | (def listv3 (cons 5 (rest listv1))) |
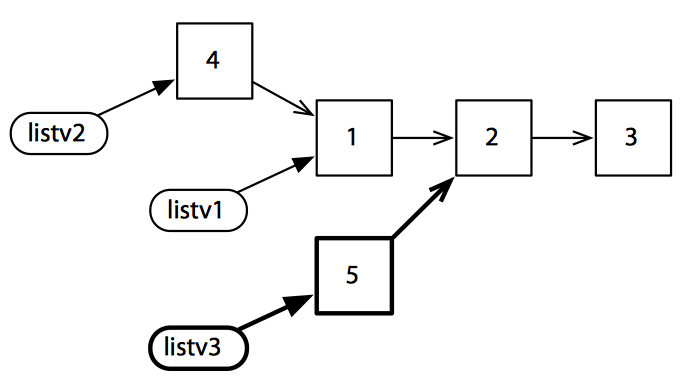
这时仅共享了原始列表的部分元素,但扔不需要进行复制。有些情况下是无法避免复制的。有共同尾端的列表可以共享结构——如果两个列表拥有不同的尾端,就只能进行复制了。
1 | (def listv1 (list 1 2 3 4)) |
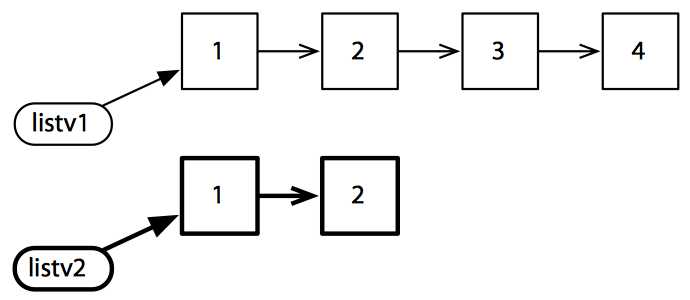
在 Clojure 中集合都是持久的。持久的 vector、map、set 在实现上都比列表复杂,但它们都使用了共享结构,且与 Ruby 或 Java 中对应的数据结构心梗接近。
标识与状态
如果一个线程引用了持久数据结构,那么其他线程对数据结构的修改对该线程就是不可见的。因此持久数据结构对并发编程的意义非比寻常,其分离了标识(inentity)与状态(state)。
油箱中有多少油呢?现在可能有一半油,一段时间后可能就空了,再后来可能又满了。“油箱中有多少油”是一个标识,其状态是一直在改变的,也就是说,实际上它是一系列不同的值。
命令式语言中,变量混合了标识与状态——一个标识只能拥有一个值。这让我们很容易忽略一个事实:状态实际上是随时间变化的一系列值。持久化数据结构将标识与状态进行了分离——如果获取了一个标识的当前状态,无论将来对这个标识怎样修改,获取的那个状态将不会改变。
重试
由于 Clojure 是函数式语言,其原子是无锁的——内部使用了 JUC.AtomicReference 提供的 compareAndSet 方法。因此使用原子变量的效率很高且不会发生阻塞,因此也不会有死锁。
但这要求 swap!(用于更新原子变量的值)需要处理这种情况:当 swap! 调用其参数函数来生成新值、但尚未修改原子变量的值时,其他线程就修改了原子变量的值。如果发生了这种情况,swap! 就需要重试。swap! 将放弃从参数函数中生成的值,并使用原子变量的新值来重新调用参数函数。因此这要求该参数函数必须没有副作用——否则,多次重试时也会多次引起这些副作用。
校验器
在创建原子变量时可以提供一个校验器。校验器是一个函数,当改变原子变量的值时就会调用它。如果校验器返回 true,就允许本次修改,否则就放弃本次修改。
校验器在原子变量的值改变生效之前被调用。与“重试”机制中传给 swap! 的参数函数类似,当 swap! 进行重试时,校验器可能会被调用多次,因此校验器不能有副作用。
监视器
可以为原子变量添加一个监视器。添加监视器时需要提供一个键值和一个监视函数。键值用于区分不同的监视器。原子变量的值被改变时会调用监视器。监视器接收四个参数——调用 add-watch 时指定的键值、原子变量的引用、原子变量的旧值、原子变量的新值。
与校验器不同,监视器是在原子变量的值改变之后才被调用,且无论 swap! 重试多少次,监视器仅会被触发一次。因此监视器可以拥有副作用。注意:监视器被调用时,原子变量的值可能已被再次改变,因此监视器必须使用参数中提供的(触发时的)新值,而不能通过对原子变量进行解引用来获取(当前的)新值。
代理与软件事务内存
下面介绍两种可变数据类型:代理(agent) 和引用(ref)。与原子变量性质相同,代理和引用都可以用于并发,也能与持久数据结构一起使用,以实现标识与状态的分离。学习引用时将介绍 Clojure 中实现的对软件事务内存的支持,使变量在无锁的情况下可以被并行的修改,同时仍保持一致性。
代理
与原子变量类似,代理包含了对一个值的引用。可以通过 deref 或 @ 获取其值。与 swap! 类似,send 接受一个函数,并用代理的当前值作为参数来调用该函数,函数的返回值再作为代理的新值。
send 与 swap! 的区别是,前者会(在代理的值更新之前)立即返回——传给 send 的函数将在某个时间点被调用。如果多个线程同时调用 send,传给 send 的函数将被串行调用:同一事件只会调用一个。也就是说该函数不会进行重试,并且可以具有副作用。
与 Actor 相似?两者存在很大的差异:
- 通过 deref 可以获得代理的值,而 actor 没有提供直接获取值的方式。
- actor 可以包含行为,而代理不可以:对数据的操作函数必须由调用者提供。
- actor 提供了复杂的错误检测和错误恢复机制,而代理仅提供了简单的错误报告机制。
- 使用多个 actor 可能会引起死锁,但使用多个代理不会。
send 的异步更新机制相比同步优势明显,尤其是当更新操作会发生阻塞或需要持续很久时。但异步更新也很复杂,尤其是在错误处理方面。
在 Clojure 中,一旦代理发生错误,就会进入失效状态,之后对代理数据的任何操作都会失败。
创建代理时其默认的错误处理模式为 fail。也可以将错误处理模式设置为 continue,这意味着失效状态的代理不再需要通过 restart-agent 重置就可以继续新的操作。如果设置了错误处理函数,错误处理模式会被默认设置为 continue,代理出现错误时则会调用错误处理函数。
软件事务内存
引用(ref)比原子变量或代理更加复杂,通过引用可以实现软件事务内存(STM)。通过原子变量和代理每次仅能修改一个变量,而通过 STM 可以多多个变量进程并发一致的修改,就像数据库中的事务可以对多行数据进行并发一致的修改一样。
引用也是包装了对一个值的引用,使用 deref 或 @ 获取值;使用 alter 函数来修改引用的值,但不同于 swap! 或 send,使用时不能只是简单的被调用。因为只能在一个事务中才能修改引用的值。
事务
STM 事务具有原子性、一致性、隔离性。
- 原子性:在其他事务看来,当前事务的副作用要么全部发生,要么都不发生。
- 一致性:事务保证全程遵守校验器定义的规范,如果事务的一系列修改中存在一个校验失败,那么所有的修改都不会发生。
- 隔离性:多个事务可以同时运行,但同时运行的事务的结果,与串行运行这些事务的结构应当完全一样。
这三个性质是许多数据库支持的 ACID 特性中的前三个,唯一遗漏的性质是——持久性,STM 的数据在电源故障或系统崩溃时会丢失。如果需要用到持久性则完全可以直接使用数据库。
隔离性选择
大多数场景适合使用完全隔离的事务,但对于有些场景来说,隔离性是个过强的约束。如果使用 commute 替换 alter,就可以得到不那么强的隔离性。
多个引用
事务通常会涉及多个引用,否则应该使用原子变量或代理。
对,你猜对了,又是银行转账的例子。
如果 STM 运行期间检测到多个并发事务的修改发生冲突,那其中一个或几个事务将进行重试。就像修改原子变量一样,需要保证事务没有副作用(除了更新引用的值意外的其操作)。
重试事务
基于无锁的重试,可以避免死锁。
事务的安全副作用
代理具有事务性。如果在事务中使用 send 来更新一个代理,那么 send 仅会在事务成功时生效。如果需要在事务成功时产生一些副作用,那 send 将是最佳选择。
适用场景
Clojure 对共享可变状态的三种支持机制:
- 原子变量:可以对一个值进行同步更新,同步的意思是当 swap! 调用返回时更新已经完成。无法对多个变量进行一致性更新。
- 代理:对一个值进行异步更新,异步的意思是更新可能在 send 返回后完成。对多个代理不能一致更新。
- 引用:可以对多个值进行一致的、同步的更新。
原子变量还是 STM
当解决一个涉及多个值需要一致更新的问题时,即可以使用多个引用并通过 STM 来保证一致性,也可以将这些值整合到一个数据结构中并用一个原子变量管理这个单个数据结构的访问一致性。
该如何选择呢?答案是因人而异,两种方案都正确,尽量选择简单的,比如数据结构肯能会很复杂。在性能上,根据使用场景的特点和数据访问模式的不同,肯定会存在差异,所以需要有效的压力测试进行评估。
虽然 STM 带有很多光芒,但就 Clojure 而言,由于语言的函数性减少了对可变量的使用,因此大部分问题都可以使用原子变量来解决。而更简单的方案通常会更有效。
总结
优点
传统的命令式语言混淆了标识与状态这两个概念,而 Clojure 的持久数据结构将可变量的标识与状态分离开来。这解决了基于锁的方案的大部分缺点。
缺点
基于 Clojure 方式的并发编程不支持分布式编程,因此也无法直接提供容错性。好在 Clojure 运行于 JVM,可以使用一些第三方库来解决该问题,比如 Akka。
其他语言
Haskell 提供了类似本章的功能,不过作为一种纯粹的函数式语言,它的风格会带来一种非常不同的编程体验。值得一提的是 Haskell 提供了完整的 STM 实现。可以参考 Beautiful Concurrency。
另外,大部分主流语言都提供了 STM 实现,包括 GCC 支持的编程语言。但是有证据表明,STM 模型并不适合于命令式编程语言。