CH02-CPU 实现
CPU 硬件为了提高性能,逐步发展出了指令流水线(分支预测)和多核 CPU,本文我们将简单的探讨它们的原理和效果。
指令流水线
在一台纯粹的图灵机中,指令是一个接一个顺序执行的。而现实世界中的通用计算机所用的很多基础算法都是可以并行的,如加法器和乘法器,它们可以很容易的被切分成能够同时运行的多个指令,这样就可以大大提升性能。
指令流水线,说白了是就是 CPU 电路层面的编发。
Intel Core i7 自 Sandy Bridge(2010)架构以来一直都是 14 级流水线设计。基于 Cedar Mill 架构的最后一代奔腾 4,在 2006 年就拥有 3.8GHz 的超高频率,却因为其长达 31 级的流水线而成了为样子货,被 AMD 1GHz 的芯片按在地上摩擦。
流水线是现代 RISC(精简指令集) 核心的一个重要设计,它极大地提高了性能。
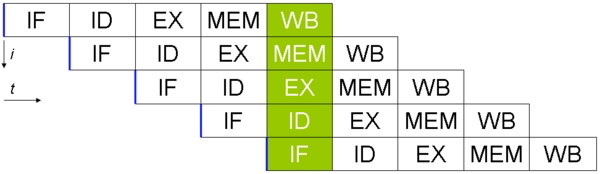
对于一条指令的执行过程,通常分为:取指令、指令译码、取操作数、运算、写结果。前面三步由控制器完成,后面两步由运算器完成。按照传统的做法,当控制器工作的时候运算器在休息,在运算器工作的时候控制器在休息。流水线的做法就是当控制器完成第一条指令的操作后,直接开始开始第二条指令的操作,同时运算器开始第一条指令的操作。这样就形成了流水线系统,这是一条2级流水线。
RISC 机器的五层流水线示意图
下图形象的展示了流水线是如何提高性能的。
缺点
指令流水线通过硬件层面的并发来提高性能,却也带来了一些无法避免的缺点。
- 设计难度高,一步小心就成了高频低能的奔腾 4。
- 并发导致每条指令的执行时间变长。
- 优化难度大,有时候两行代码的顺序变动可能导致数倍的性能差异,这对编译器提出了更高的要求。
- 如果多次分支预测失败,将会导致严重的性能损失。
分支预测
指令形成流水线以后,就需要一种高效的调控来保证硬件层面的并发效果:最佳情况是每条流水线里的十几个指令都是正确的,这样完全不浪费时钟周期。而分支预测就是干这个的。
分支预测器猜测条件表达式两路分支中那一路最优可能发生,然后推测执行这一路的指令,来避免流水线停顿造成时间的浪费。但是,如果后来发现分支预测错误,那么流水线中推测执行的那些中间结果就要全部被放弃,重新获取正确的分支路线上的指令开始执行,这就带来了是一个时钟周期的延迟,这个时候,该 CPU 核心就是完全在浪费时间。
幸运的是,当下主流的 CPU 在现代编译器的配合下,能够越来越高的完成这项工作。
还记得那个让 Intel CPU 性能跌 30% 的漏洞补丁吗,那个漏洞就是 CPU 设计的时候,分支预测设计的不完善导致的。
多核 CPU
多核 CPU 的每个核心拥有自己独立的运算单元、寄存器、一二级缓存,所有核心共用同一条内存总线,同一段内存。
多核 CPU 的出现,标志着人类的集成电路工艺遇到了一个严酷的瓶颈,无法再大规模提升单核性能,只能通过多核类聊以自慰。实际上,多核 CPU 性能的提升极其有限,还不如增加一点点单核频率所能提升的性能多。
优势
多核 CPU 的优势很明显,就是可以并行地执行多个图灵机,可以显而易见地提升性能。只不过由于使用同一条内存总线,实际带来的效果有限,并且需要操作系统和编译器的密切配合才行。
题外话: AMD64 技术可以运行 32 位的操作系统和应用程序,所用的方法是依旧使用 32 位宽的内存总线,每计算一次要取两次内存,性能提升也非常有限,不过好处就是可以使用大于 4GB 的内存了。大家应该都没忘记第一篇文章中提到的冯·诺依曼架构拥有 CPU 和内存通信带宽不足的弱点。(注:AMD64 技术是和 Intel 交叉授权的专利,i7 也是这么设计的)
劣势
多核 CPU 劣势其实更加明显,但是人类也没有办法,谁不想用 20GHz 的 CPU 呢,谁想用这八核的 i7 呀。
- 内存读写效率不变,甚至有降低的风险。
- 操作系统复杂度提升很多倍,计算资源的管理变得非常复杂。
- 依赖操作系统的进步:微软以肉眼可见的速度,在这十几年间大幅提升了 Windows 的多核效率和安全性:XP 只是能利用,7 可以自动调配一个进程在多个核心上游走,2008R2 解决了依赖 CPU0 调度导致司机的 BUG,8 可以利用多核心启动,10 优化了杀死进程依赖 CPU0 的问题。
超线程技术:Intel 的超线程技术是将 CPU 核心内部再分出两个逻辑核心,只增加了 5% 的裸面积,就带来了 15%~30% 的性能提升。
怀念过去
Intel 肯定怀念摩尔定律提出时候的黄金年代,只依靠工艺的进步,就能一两年就性能翻番。AMD 肯定怀念 K8 的黄金一代,1G 战 4G,靠的就是把内存控制器从北桥芯片移到 CPU 内部,提升了 CPU 和内存的通信效率,自然性能倍增。而今天,人类的技术已经到达了一个瓶颈,只能通过不断的提升 CPU 和操作系统的复杂度来获得微弱的性能提升,呜呼哀哉。
不过我们也不能放弃希望,AMD RX VAGA64 显卡拥有 2048 位的显存位宽,理论极限还是很恐怖的,这可能就是未来内存的发展方向。